
Decoding the Genetic Code - Part 1
Decoding the Genetic Code - Part 1
"How your DNA works" Edited Aug 11, 2022

We are finally emerging from the COVID-19 pandemic. But also emerging are some fundamental understandings of the origins of the virus and the biological modes of operation of the virus, first at a cellular level and then at a “whole body” (system) level. If you are reading the material with an inadequate understanding of the fundamentals, you are probably missing much of the more nuanced information. That may leave you to just follow the most popular “authorities” without the confidence of making critical decisions on your own. Once you have some adequate basics, you at least begin to “know what you don’t know”, and to pay close attention to what is important. With that in mind, I want to explore some basic understandings that will help you to better “digest” the massive amounts of information that is available. There are also a lot of very articulate “experts” on the web. Yes, there are indeed “conspiracy theories” out there, but there are also a lot of things that I never thought I would see in my lifetime.
The Universal Genetic Code
The Genetic Code is identical in virtually every known living organism, from cucumbers to humans. The exceptions are few and small, and often only involve “repurposing” one of the three stop codons. A gene is a sequence of DNA base-pairs that is transcribed into a messenger RNA (mRNA) segment. This mRNA is transported to a ribosome, the “protein factory” of the cell. Sequences of three nucleotide base pairs are called a codon. Each codon specifies one specific amino acid. This is about as brief of a summary possible of a vastly complex subject.
The mRNA “Vaccines” use a modified form of mRNA (modRNA) where some of the Uridine (U) is replaced by N1-MethylPseudoUridylation of mRNA causes +1 ribosomal frameshifting. (https://www.nature.com/articles/s41586-023-06800-3)
The DNA of humans is composed of approximately 3 billion base pairs, making up a total of almost a 6-foot-long stretch of DNA in every one of the (typically) 50 trillion cells in the typical adult body.
One interesting observation is that there are only four “letters” in the DNA “alphabet”. In DNA, the purine bases are adenine (A) and guanine (G), while the pyrimidines are thymine (T) and cytosine (C). The mRNA copy uses uracil (U) in place of thymine (T). Since each letter in a codon has four possibilities and there are three letters in a codon, that means that there are 64 possible code combinations (4^3) of three “letters”, as listed in this table:
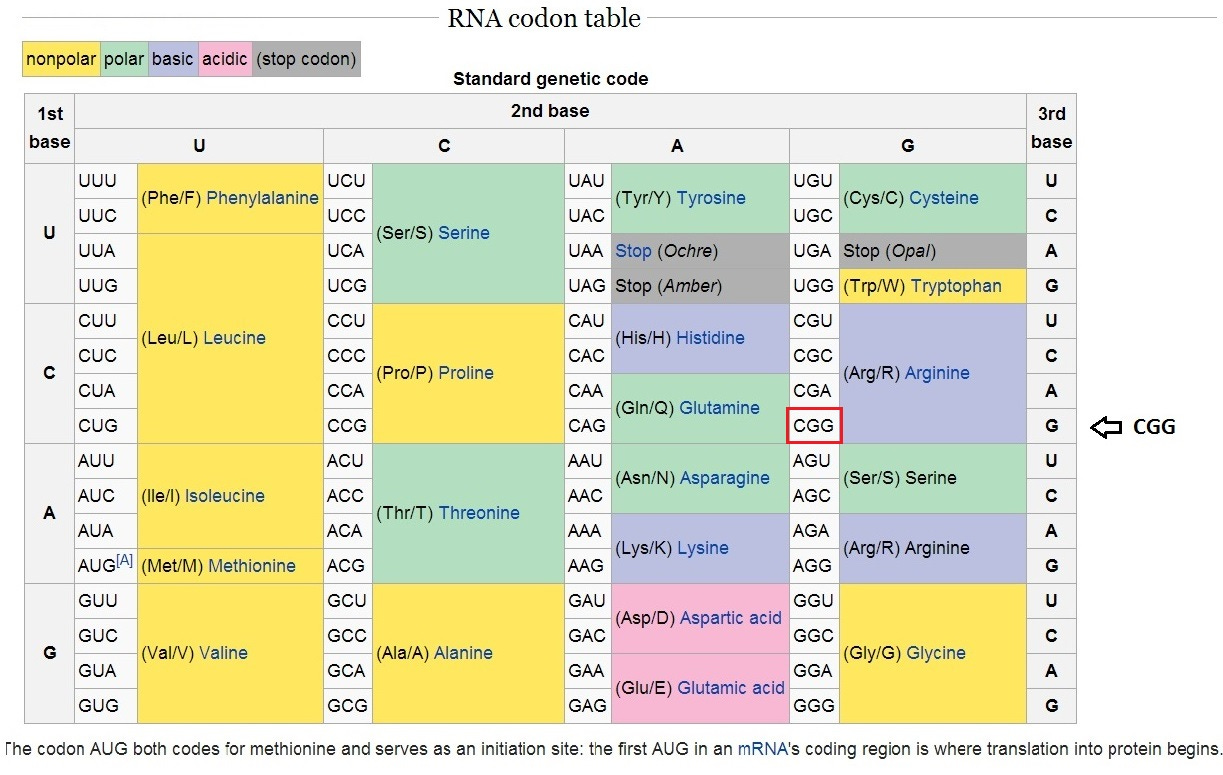
Fig. 1 The Standard Genetic Code
The table is remarkably “mathematical”. This is easier to see if I simply replace U or T with a 1, C with a 2, A with a 3 and G with a 4. Now Valine (lower left) is number 411, 412, 413 or 414.
[1]One codon is used to mark the START point: AUG codes for methionine and also marks the starting point of a gene. There are three valid STOP markers (UAA, UAG, UGA) which do not call for an actual amino acid -- they simply tell the “production line” where to stop. That leaves 60 codes for 20 amino acids, or an average of three codes per amino acid. In actuality some amino acids are more heavily represented (Leucine, Arginine and Serine with 6 codes; Valine, Proline, Threonine, Alanine and Glycine with four). That means that some have only two codes.[2] Methionine has only one codon, and it is actually the “START” codon.
Interestingly, this “Genetic Code” table DOES NOT EXIST anywhere in your genome. Scientists had to painstakingly piece it together by observing which amino acid any given codon actually specified. Whenever “CGG” appears in a gene sequence, you will find a Arginine amino acid at that corresponding position, as in the code table above..

The tRNA molecule can be thought of as a “cowboy”. It “rounds up” a matching amino acid (Alanine, in this case) and herds it in to the ribosome. It has a matching anti-codon (GGC) on its “foot”. When there is a matching codon (CCG), it drops in and deposits the matching amino acid into the forming amino acid string while holding it in the proper orientation so that the ribosome can “glue” it in place. The ribosome then ejects the empty tRNA to go find another alanine and moves the mRNA to the next codon. So they carefully searched for a match between rather short genes and rather small proteins. Once they found such a match, they had a good portion of the table filled, and those matches made it easier to find more.
In the language of DNA, there are three-letter words called codons that specify the amino acids of proteins. A gene “sentence” is made up of these three-letter words, in typical lengths of 100 to 500 or more amino acids. The ribosome is a highly complex “automated machine” that “reads” the letters on 3-letter codons and assembles the next specified amino acid into the growing chain. This is a highly automated assembly line.
There is one fundamental problem with three-letter codons: you must know where to start. Consider the sentence, “The cat ate the rat.” There are no spaces between the codons, so it would be written “thecatatetherat”. If the cell started reading at the wrong point, “hec ata tet her at…” makes no sense at all when read as "codons". Neither would the totally scrambled "protein" it generated. In fact, it would not fold into a stable final shape. But what would happen if a mutation accidentally inserted or deleted one nucleotide base pair? These mutations are referred to as “indels” – for "insertions and deletions". In like manner, from the point of the indel to the end of that gene, the coding is totally scrambled and meaningless. “Thexcatatetherat” becomes “The xca tat eth era t” This is a frame shift error, and it is virtually always catastrophic because the reading process is thrown “out of sync”. The chances that it can fold into a stable protein are essentially zero. The ending STOP codon would also be frame-shifted, so the ribosome no longer even knows where to stop. It will simply try to decode the “Poly (A) trailer” of the mRNA into actual amino acids. But since a large portion of the protein has been changed very randomly, the original function is of course completely destroyed.
[1] Much of this discussion comes from The Cell's Design by Fazale Rana (Colorado Rapids, Baker Books, 2008). Available from Amazon. Page number references are from this book.
[2] pp 172-176
There were many profound surprises along the way in “Decoding the Genetic Code”. We will explore some of them… Research has shown that the genetic code is actually highly optimized to minimize errors. Given the serious problems caused by transcription errors, error minimization would certainly be expected in any data system designed by human engineers. But how can that happen in an “unguided, random system”? Error minimization requires an immense amount of highly intelligent pre-planning.

Fig. 2. Error Minimization is highly optimized
But any attempt to explain it in terms of natural selection immediately runs into serious trouble. A random "first cut" version of the genetic code would be expected to fall somewhere in the "bell curve" of random codes[1]. Instead it falls far out in the "extremely good" range. Back as far as 1968, Dr. Francis Crick himself pointed out[2] that any significant optimizing of the code seems virtually impossible. To understand the problem, consider even doing the optimization "intelligently", let alone randomly. If you decide to take only one codon and re-assign it to another amino acid, that will cause multiple changes in virtually every protein in the entire genome. Let me illustrate:
Imagine that after much thought and statistical analysis you decide that it would be advantageous to reassign one of the six codes for Leucine (CUG) to Glutamine instead. There are a total of 60 codes available for the 20 amino acids so there are an average of 3 codes per amino acid, so Leucine is still comfortably over-represented. To accomplish this we would have to locate the code for building the CUG transfer RNA (tRNA) and reprogram the “top” end of it to grab onto Glutamine instead of Leucine. That way, when mRNA calls for a “CUG”, Glutamine will be delivered instead of Leucine. Remember that your average protein is about 485 amino acids long according to one estimate, so 1/60 of these amino acids will suffer a mutation. So all 20,000+ of your proteins would suffer 8 mutations in every average protein, and much more in the large proteins.
This would most certainly be fatal to the organism! And yet, any significant optimization would require a very large number of these "experimental" optimizations. So every attempt to optimize the genetic code will almost certainly be grossly disadvantageous and thus would be rejected by “natural selection”. Also, ongoing optimizations would almost certainly result in a diversity of genetic codes, since differing "partly optimized" versions would become geographically isolated.
Here is another problem: Even if one species (an eel for example) came up with a highly optimized genetic code by random unguided trial-and-error, there is no reason to believe that this would force the shark to adapt that code. There is no procedure for “transferring” the genetic code in the first place, but transplanting a significantly “improved” code would instantly cause huge numbers of “mutations” to virtually every protein in the recipient’s genome.
Another obvious problem is that once the code is moderately well optimized, the majority of random changes will more likely tend to make it worse. The more finely the code is optimized, the smaller the improvements become, and hence the lower the “evolutionary pressure” for that code to prevail.
Explaining code optimization is a profound conundrum for evolutionists.
“Survival of the Fittest”
While we are on the subject, we should dispense with this silly slogan. (1) The statistics of survival for all but the most dramatic “improvements” would be overwhelmingly dominated by random local predators in the rain forest. (2) Incremental evolutionary steps would have negligible effect on longevity or dominance and would be competing with a host of other small contenders. Thus many “small evolutionary improvements” would be lost forever. But the rest should be left for another paper…
Bad Xerox Copies?
What happens when there is an error in transcription? Your genome is over 3 billion “letters” long, and the copy process seems to proceed at a breakneck speed. Inevitably, there are a significant number of errors, but I will discuss that shortly. The error minimization actually takes several forms. The optimized code assignments are obviously not random, as an "evolutionary first guess" would be. The redundant codes (as many as six for some amino acids) mean that there are many possible code errors in the "second and third digits" that do not actually result in a changed amino acid. This redundancy in the code has an interesting effect on the discussion of protein evolution.
But the optimization goes further. Statistically, changes that do actually substitute a different amino acid tend to substitute one that is minimally different[3]. So while that may slow down the folding a bit or decrease the efficiency of an enzyme marginally, life generally goes on. Most of these mutations do not change the shape of the final folded protein significantly. The effects of mutations could be much worse with an un-optimized genetic code. Or, to look at in another way, these error-minimizing optimizations of the code drastically slow down the “progress” of Darwinian Evolution. This is certainly NOT what they expected to find…

Fig. 3 The 20 Amino Acids
This optimization gives a very strong impression that the grand plan must have been designed by some intelligent source. But impressions can of course be misleading, or they can frankly be quite biased. So we need to maintain a high threshold for "impressions". Every individual -- whether it is conscious or not -- has two thresholds. There is a negative threshold where I reject an explanation or theory outright. There is a positive threshold where I become strongly convinced. And of course, there is a gray area of uncertainty in between. What I find is that this impression (the code optimization) is so pervasive and so consistent that I cannot dismiss it lightly with, "Isn't it amazing what a million years of evolution can accomplish?" Frankly, I am not convinced that it can. That sort of shallow rationalization is not science. Even Dr. Francis Crick acknowledged that it seemed impossible.
[1] The Cell's Design by Fazale Rana (Colorado Rapids, Baker Books, 2008). Available from Amazon. Page 176
[2] p.176: F.H.C. Crick, "The Origin of the Genetic Code," Journal of Molecular Biology 38 (December 1968): 367-79.
[3] p 174
You can think of the code optimization[1] as a "passive" form of error minimization. Once implemented, it requires no further thought or planning. But there are features that go far beyond simply passive. Arginine, Serine and Leucine can each be "spelled" six different ways. On the average any amino acid can be "spelled" three different ways. This is done by simply substituting one of the alternate codes that specify the same amino acid. This provides a tremendous flexibility in "spelling" a protein. A protein with a length of 100 residues can be "spelled" roughly 3^100 ways. That is 5 x 10^47 ways to "spell" the same protein. But even any segment as short as 12 base pairs (4 amino acids) can be "spelled" about 81 ways and any segment of 6 base pairs (just two amino acids) can be written 9 different ways. Why is this important? As one example, a long alpha helix is a long repetitive series of short amino acid sequences. I have read that these long repetitive series are for some reason more prone to copying errors. But with the built-in redundancy it becomes possible to vary the sequence significantly. Varying the "spelling" in the long sequences reduces the probable error rates even further. Who would have guessed? Proteins that "evolved randomly" would not "know" that they have additional sets of rules and constraints as to how their gene must be coded.


But developing a set of rules that would allow correcting random errors is many orders of magnitude more difficult. In his book, The Cell's Design, Fazale Rana describes the intricate quality control systems that detect errors in coding or folding, and then either repair the problem or tag the defective proteins for destruction and recycling their amino acids. The overview of the cell's "factory" far exceeds the best ISO9001 "mil spec" production facilities.
In the next installment, I will explore some of the mysteries and surprises of the gene-copying process.